一.引子
在这里「增量」这个概念的对立面是「全量」。在 Linux 系统中当需要备份数据或者跨服务器同步文件时,会用到一个叫 rsync 的工具,它的速度会比 scp/cp 命令更快,因为它会先判断已经存在的数据和新数据的差异,只传输不同的部分,即「增量」同步。
在前端开发工程化领域,本文将介绍用「增量」思想提升代码检查、打包构建环节的速度,从而实现开发过程的效率提升。
二.增量代码检查
前端使用 ESLint 做代码规范静态检查。随着前端工程化的发展,我们会将代码检查与开发工作流集成,在代码提交前和代码交付前自动做 ESLint 检查。代码提交检查即在开发者每一次 commit 时通过 git hooks 触发 ESLint 检查,当工程代码量很大时开发者每一次提交代码甚至要等数分钟时间才能检查完。代码交付检查即借助持续集成流程,比如在 MR 时触发代码检查,这是会阻断 MR 的流程的,经常会出现这样一种情况,某个 MR 仅仅修改了一行代码,却要扫瞄整个项目,这会严重影响持续集成的效率。所以大部分情况下并不需要进行 ESLint 的全量扫描,我们更关心的是新增代码是否存在问题。
接下来我们通过自定义 git 的 pre-commit 钩子脚本来为一个工程实现增量代码提交检查能力。
2.1 寻找修改的文件
本脚本中 ESLint 检查执行到文件这一粒度。实现增量代码检查首先就是要能找到增量代码,即修改了哪些文件。我们借助 git 版本管理工具寻找提交时暂存区和 HEAD 之间的差异,找到修改的文件列表。
- 使用
git diff找到本次提交修改的文件,加--diff-filter=ACMR参数是为了去掉被删除的文件,删除的文件不需要再做检查了; - 使用 child_process 模块的 exec 函数在 node 中执行 git 的命令;
- 输出的是由修改的文件组成的字符串,做简单的字符串处理提取出要检查的文件列表;
const exec = require('child_process').exec;
const GITDIFF = 'git diff --cached --diff-filter=ACMR --name-only';
// 执行 git 的命令
exec(GITDIFF, (error, stdout) => {
if (error) {
console.error(`exec error: ${error}`);
}
// 对返回结果进行处理,拿到要检查的文件列表
const diffFileArray = stdout.split('\n').filter((diffFile) => (
/(\.js|\.jsx)(\n|$)/gi.test(diffFile)
));
console.log('待检查的文件:', diffFileArray);
});2.2 对被修改的文件进行代码检查
ESLint 提供了同名类函数(ESLint)作为 Node.js API 调用(低于 7.0.0 版本使用 CLIEngine 类),这样我们能在 node 脚本中执行代码检查并拿到检查结果。
- 使用 ESLint 的 lintFiles 函数对文件列表进行代码检查;
- 返回的结果是个数组,包含每个文件的检查结果,对数组进行处理拿到检查结果并输出提示;
const { ESLint } = require('eslint');
const linter = new ESLint();
// 上文拿到待检查的文件列表后
let errorCount = 0;
let warningCount = 0;
if (diffFileArray.length > 0) {
// 执行ESLint代码检查
const eslintResults = linter.lintFiles(diffFileArray).results;
// 对检查结果进行处理,提取报错数和警告数
eslintResults.forEach((result) => {
// result的数据结构如下:
// {
// filePath: "xxx/index.js",
// messages: [{
// ruleId: "semi",
// severity: 2,
// message: "Missing semicolon.",
// line: 1,
// column: 13,
// nodeType: "ExpressionStatement",
// fix: { range: [12, 12], text: ";" }
// }],
// errorCount: 1,
// warningCount: 1,
// fixableErrorCount: 1,
// fixableWarningCount: 0,
// source: "\"use strict\"\n"
// }
errorCount += result.errorCount;
warningCount += result.warningCount;
if (result.messages && result.messages.length) {
console.log(`ESLint has found problems in file: ${result.filePath}`);
result.messages.forEach((msg) => {
if (msg.severity === 2) {
console.log(`Error : ${msg.message} in Line ${msg.line} Column ${msg.column}`);
} else {
console.log(`Warning : ${msg.message} in Line ${msg.line} Column ${msg.column}`);
}
});
}
});
}
2.3 友好的提示及错误处理
- 在命令行界面做友好的输出提示,本次代码检查是否通过;
- 如果检查结果存在错误,就以非 0 值退出,git 将放弃本次提交。
if (errorCount >= 1) {
console.log('\x1b[31m', `ESLint failed`);
console.log('\x1b[31m', `✖ ${errorCount + warningCount} problems(${errorCount} error, ${warningCount} warning)`);
process.exit(1);
} else if (warningCount >= 1) {
console.log('\x1b[32m', 'ESLint passed, but need to be improved.');
process.exit(0);
} else {
console.log('\x1b[32m', 'ESLint passed');
process.exit(0);
}
到这里 pre-commit 钩子脚本就完成了,只需要在 package.json 文件中配置下脚本的执行就能实现增量代码检查了。最终实现的效果是开发者在提交代码时再也不用等待全量代码检查完成了,脚本会很快找到有改动的文件并检查完。
如果想要在自己的项目中实现这一功能,可以直接使用开源库 lint-staged 结合 husky 一起用。
代码交付时的增量检查实现方式和上面的步骤类似,关键点就是找到增量的部分。
2.4 结果对比
以一个包含 460 个 js 文件的中等规模工程为例,下图中左边为全量代码检查的耗时,右边为增量代码检查的耗时:
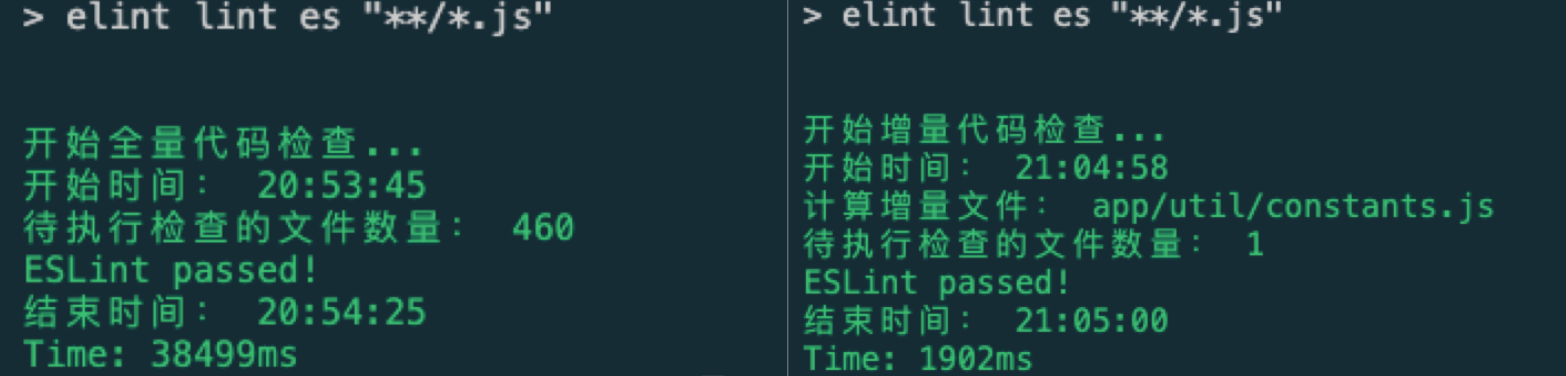
如果开发者只修改了一个文件,在提交代码时全量检查需要耗时 38 秒,而增量检查只需要耗时 2 秒。
2.5 更细粒度的增量检查
前文实现了文件粒度的增量检查,考虑到大型项目中可能存在很多大文件,如果只修改了几行代码就需要对整个文件进行 ESLint 检查依然是个低效的操作,我们可以尝试找到代码行粒度的增量代码做检查。
首先仍然用 git diff 命令找到修改的部分,这里需要做一些字符串的处理提取出代码块;然后使用 ESLint Node.js API 中的 lintText 方法对代码块做检查。感兴趣的同学可以自己尝试实现一下哦。
三.增量打包构建
考虑这样一个业务场景,在一个有数百个页面的大型多页 Web 应用中(MPA),每一次全量打包构建都需要几十分钟的时间。有时候开发者只改了一个页面或者一个公共组件,却需要等上很久才能发布上线,严重影响持续集成、线上问题解决的效率。
以使用 webpack 进行打包构建为例,我们同样尝试用「增量」思想来优化这个问题。
3.1 寻找修改的文件
和前文类似,第一步依旧是找到增量代码,即本次发布修改了哪些文件。最简单的仍然是选择用 git diff 命令来实现。和增量代码检查不一样的是,这里要对比待发布的集成分支和主干,找到之间的差异文件列表。
const execSync = require('child_process').execSync;
const path = require('path').posix;
const GITDIFF = 'git diff origin/master --name-only';
// 执行 git 的命令
const diffFiles = execSync(GITDIFF, {
encoding: 'utf8',
})
.split('\n')
.filter((item) => item)
.map((filePath) => path.normalize(filePath));
获得了修改的文件列表后,并不能直接触发 webpack 打包,需要根据文件之间的引用关系找到入口文件,把需要重新打包的页面入口传给 webpack。3.2 计算增量入口
思路是先构建每个页面入口文件的依赖树,如果这棵树包含了上述被修改的文件,就说明这个页面需要被重新打包。如图所示:
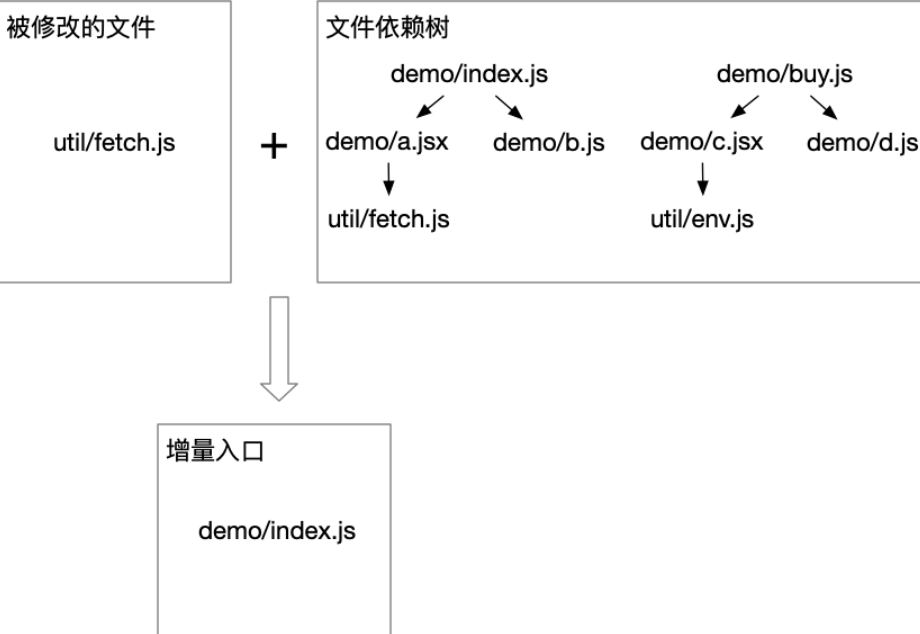
被修改的文件前文已经能获取到,接下来是要构建每个入口文件的依赖树。前端模块化规范很多,自己去实现每个文件的依赖分析需要兼顾各种情况,这里推荐一个开源库 Madge,它将代码转成抽象语法树进行分析,最终返回一棵依赖树。
以上图中两个入口文件为例,它们的依赖树如下:
// 被修改的文件列表
const diffFiles = ['util/fetch.js'];
// 用 madge 库计算依赖树的示例代码,具体可查看官方文档
// Promise.all([madge('./demo/index.js'), madge('./demo/buy.js')]).then((result) => {
// result.forEach((e) => {
// console.log(e.obj());
// })
// });
// 最后得到的依赖树如下
const relyTree = {
// demo/index.js 文件的依赖树
{
'demo/a.jsx': ['util/fetch.js'],
'demo/b.js': [],
'demo/index.js': ['demo/a.jsx', 'demo/b.js'],
'util/fetch.js': []
},
// demo/buy.js 文件的依赖树
{
'util/env.js': [],
'demo/buy.js': ['demo/c.js', 'demo/d.js'],
'demo/c.js': ['util/env.js'],
'demo/d.js': []
}
};
深度遍历每个入口文件的依赖树,根据是否包含被修改的文件列表中的文件来判断是否需要重新打包构建,示例代码如下:
/* 计算增量入口示例代码 */
// 全量页面入口
const entries = [
'demo/index.js',
'demo/buy.js',
];
// 判断两个数组是否存在交集
function intersection(arr1, arr2) {
let flag = false;
arr1.forEach((ele) => {
if (arr2.includes(ele)) {
flag = true;
}
});
return flag;
}
// 计算增量入口
const incrementEntries = [];
for (const i in relyTree) {
for (const j in relyTree[i]) {
if (intersection(relyTree[i][j], diffFiles)) {
incrementEntries.push(i);
}
}
}比如我们已知本次发布是修改了 util/fetch.js 这个文件,遍历以上 2 个依赖树就得知只有 demo/index 这个页面受影响,修改 webpack 的配置只把这个文件作为入口参数触发打包就可以极大提升打包构建的速度。
3.3 边界情况
前端工程还有一些依赖是 package.json 文件里描述的 npm 包,安装在 node_modules 文件夹里,模块之间的依赖关系非常复杂。简单起见,当第一步 git diff 发现 package.json 里有模块升级时,考虑到这不是高频事件,可以直接触发全量打包。
3.4 结果对比
以一个包含 50 个页面的 MPA 工程为例,下图中左边为全量打包构建的耗时,右边为增量打包构建的耗时: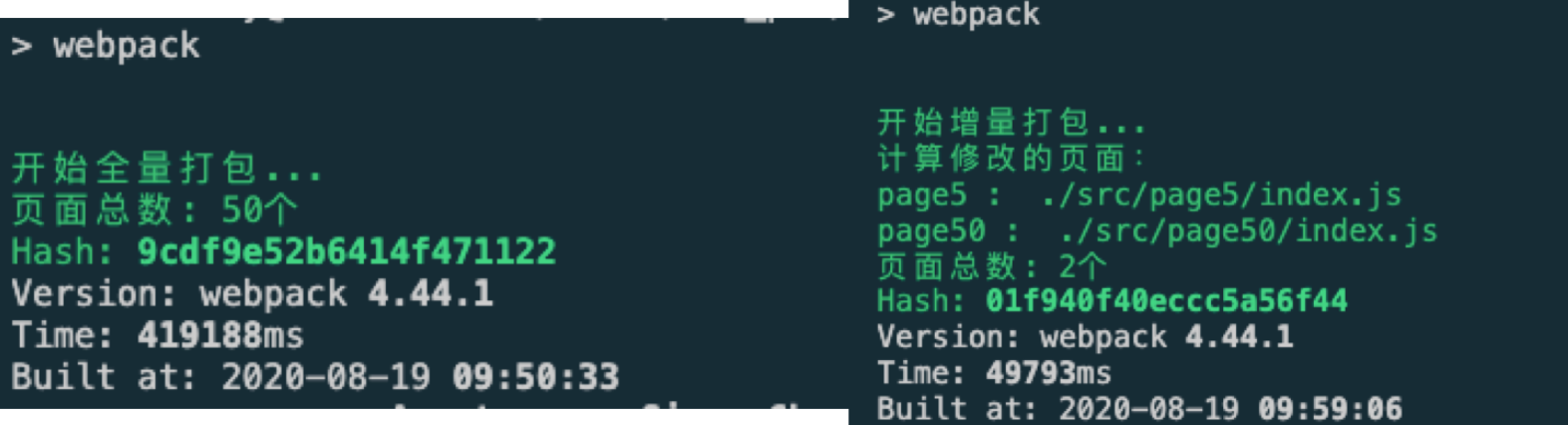
小结
本文以增量代码检查和增量打包构建两个特定业务场景为例,介绍了「增量」思想在前端开发工程化中如何做效率提升。这两个案例不一定能直接照搬到大家的前端工程化实践中去,旨在介绍这样一种编程设计思想,大家可以发挥各自的想象力运用到更多的地方。






{kind=link}
{kind=link}
留言
您必须登陆 才能发表评论。